Neural networks power some of today’s most advanced AI applications, from voice assistants to recommendation engines. At their core lie two critical components that make learning possible: weights and biases. These parameters are often glossed over in high-level discussions, but they are essential for the network to learn from data and perform accurate predictions.
This article demystifies how weights and biases function inside neural networks and why they are foundational to artificial intelligence systems.
Tech leaders evaluating AI integration.
Product managers or analysts learning ML terminology.
Students and researchers in computer science or AI.
- Weights and biases are the core learning parameters in neural networks.
- Weights adjust the importance of input signals.
- Biases allow flexibility in predictions and improve model accuracy.
What Are Weights?
Weights are the numbers a neural network learns to decide what to pay attention to. Every connection between neurons has a weight: if it’s large and positive, that input pushes the prediction up; if it’s negative, it pushes the other way; if it’s near zero, the model mostly ignores it. During training, these weights are nudged up or down so the network amplifies useful signals and suppresses noise, steadily improving its predictions.
A simple way to think about it: weights act like volume knobs on features. In a spam filter, words like “free” or “winner” may get higher weights, while “invoice” might get a negative one. In image models, tiny grids of weights scan a picture and light up when they see patterns like edges or textures. Over many training steps, helpful patterns get stronger weights, unhelpful ones fade, and the model learns which parts of the input truly matter. Combined with a bias (a small offset that shifts the decision threshold), weights let the network make flexible, accurate decisions across many kinds of data.

What Are Biases?
Biases are small numbers each neuron (or filter) adds after combining the inputs with their weights. They act like a baseline/offset, shifting the activation up or down so the model isn’t forced to make decisions only when inputs are large. In simple terms: if weights say what matters, the bias decides when the neuron should fire. With a bias, a model can fit patterns that don’t pass through the origin and set a sensible default even when inputs are near zero.
In practice, the bias controls the threshold. In a spam classifier, the bias reflects the default tendency (e.g., “not spam” unless strong evidence appears); nudging it changes how much evidence is needed to switch the prediction. In a convolutional layer, the bias sets how strong an edge or texture must be before the filter activates. Biases also help with calibration: small adjustments can align predicted probabilities with reality and reduce false positives/negatives—often without retraining everything.

Why Are Weights and Biases Important?
Weights and biases are the levers a neural network learns. They don’t just make the math work—they determine what patterns the model can represent, how stable training is, and whether predictions are useful in the real world.
- They define what the model can express.
Weights shape decision boundaries: increasing or decreasing a weight tells the model to care more or less about a feature. The bias shifts that boundary up or down, letting the model make a positive prediction even when inputs are small, or require stronger evidence when needed. Without a bias, a classifier is forced to pass through the origin—often an unnecessary constraint that hurts accuracy. - They drive training dynamics and stability.
During backpropagation, gradients flow through weights and biases. Good initial scales and healthy bias terms keep activations in a learnable range, avoid “dead” neurons, and help optimizers converge. Normalization layers (BatchNorm/LayerNorm) even add their own learnable scale/shift—extra “weights and biases”—because controlled activation ranges make learning faster and more reliable. - They control generalization (not just fit).
Models can memorize noise with overly large or mis-scaled weights. Regularization (e.g., weight decay) and proper bias use help the network capture signal instead of artifacts. In practice, keeping weight norms reasonable and calibrating final-layer biases often improves real metrics like recall at a fixed false-positive rate. - They improve calibration and thresholds in production.
Many business decisions are thresholded (approve a transaction, flag a defect, route a ticket). Final-layer weights determine class separation; the bias sets the baseline. Small bias adjustments can align predicted probabilities with reality, reducing costly false positives/negatives without retraining the whole model. - They make models inspectable.
Weights encode what features or tokens the model relies on; biases often reflect class priors. Inspecting them (or their summaries) helps with debugging drift, explaining predictions, and meeting governance requirements. In conv nets, filters reveal what patterns are detected; in language models, embeddings (which are weights) capture semantic structure.
Ready to dive deep into neural network intelligence?
Contact UsVisual Applications
Imagine you’re perfecting a recipe.
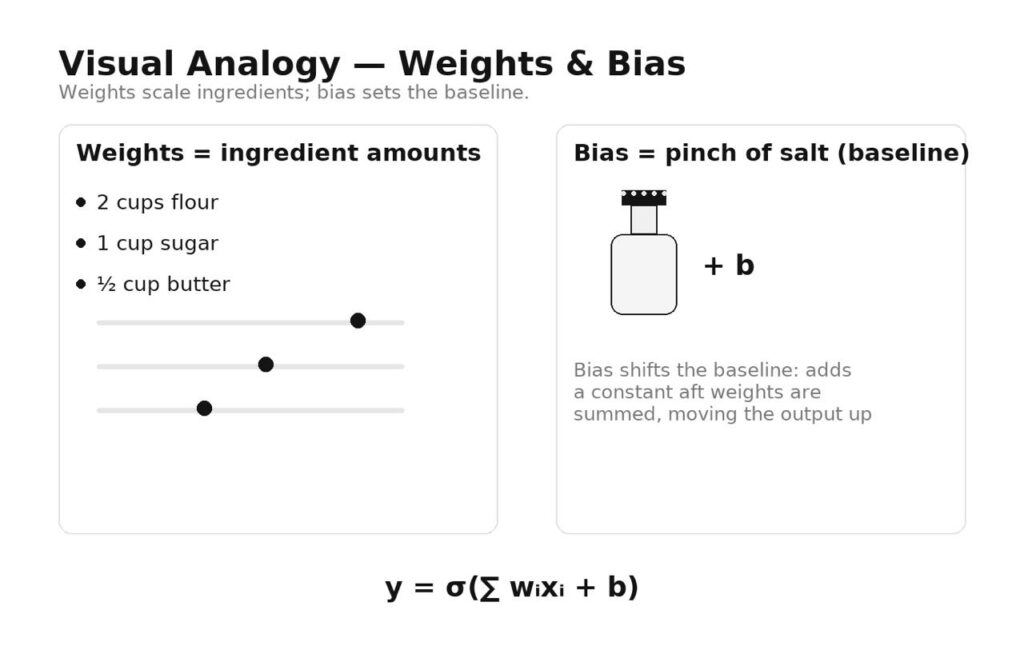
Weights = ingredient amounts.
Each input feature is like an ingredient: flour, sugar, butter. The weight says how much of that ingredient you add. Double the weight for sugar and the cake gets sweeter; reduce the weight for butter and it gets drier. During training, the model keeps nudging these amounts up or down to improve the “taste” (its predictions).
Bias = the constant pinch.
The bias is the small, fixed tweak you add no matter what—like a pinch of salt or a squeeze of lemon. It doesn’t depend on any particular ingredient; it’s a baseline adjustment that shifts the overall flavor so the result lands in the right zone. Mathematically, it’s the “+ b” that’s added after all the weighted ingredients are summed.
Why both matter.
If you only adjust ingredient amounts (weights) and never add that fixed pinch (bias), your recipe is forced to pass through “zero seasoning” when ingredients are small—often missing the sweet spot. The bias lets the chef set a baseline flavor so the dish tastes right even when inputs are modest.
Real-World Applications
Image recognition.
Convolution weights become edge/texture/shape detectors; deeper layers compose them into objects. Biases set activation thresholds so filters fire only when evidence is strong. In practice: cleaner class separation, fewer false positives after calibrating the final layer’s bias.
Language models.
Embedding and attention weights decide which tokens and positions matter most; output-layer biases encode baseline token/class frequencies. Fine-tuning shifts these weights toward domain terms; small bias tweaks (“logit bias”) can curb over- or under-generation of specific tokens.
Finance.
Model weights learn relationships among indicators (lags, volume, spreads, macro factors); the bias captures the baseline (e.g., average drift). Regularization keeps weights from chasing noise; periodic recalibration of the final bias improves thresholded decisions (risk flags, alerts) as regimes change.
Bottom line.
Across domains, the network learns weights to capture signal and biases to set sensible baselines—together yielding accurate, stable predictions.
Conclusion
Weights and biases may seem like technical minutiae, but they are the backbone of how neural networks learn and function. Mastering their role is key to understanding—and building—AI systems that work.
Whether you’re just starting your ML journey or refining production-grade models, a strong grasp of these concepts lays the groundwork for success.
Why Ficus Technologies?
At Ficus Technologies, we design and deliver intelligent systems that don’t just work—but learn and evolve. Our AI solutions rely on well-trained models where weights and biases are carefully optimized to deliver real-world impact, whether it’s through recommendation engines, predictive analytics, or process automation.
We also prioritize transparency—helping our clients understand the AI building blocks so they can make informed, strategic decisions.
No. Weights and biases are essential components of every learnable layer in a neural network. Without them, the model cannot adapt to data.
Through an algorithm called backpropagation, which uses the error from predictions to adjust weights and biases to improve performance.
While technically optional, biases are usually included in every layer because they improve flexibility and model performance.
Poor initialization can cause training to be slow or stuck. That’s why modern frameworks use specific initialization techniques like Xavier or He initialization.